

We Built Netflix-Style Recommendations Without a Single LLM Call
A founder's public story of building ExecReps.ai

It was all there. I remember the screen, the cursor blinking, a beautifully crafted system prompt sitting in my editor. Ready to pipe user profiles into GPT–4. Ready to get back personalised content recommendations. Token costs calculated, latency projections modeled, two days to ship.
Then I hit delete.
That single action, hitting delete, was one of the best product decisions I’ve made on ExecReps. Maybe it’s also the most contrarian thing I’ll write in this entire series.

The Seduction of the Easy Answer
Nobody talks about this in product right now. LLMs have become the new ‘just throw it in a database.’ Every feature. Every recommendation. Every personalisation decision. The default instinct in 2026 is to ask a model. I get it, I’ve done it too. ExecReps uses GPT–4 for assessment, and it’s brilliant there.
But recommendations are a different beast.
When we started planning personalisation, that moment a user logs in and sees curated practice scenarios instead of a generic wall of content, the temptation was overwhelming. Embed the user’s profile. Embed the content. Cosine similarity. Done. Ship it. Put ‘AI-powered recommendations’ on the marketing site.
Except I kept hitting one problem I recognized from Don Norman’s work. I couldn’t explain why the model would recommend what it recommends. Norman calls this the Gulf of Evaluation, the gap between what the system did and why it did it. I wonder if this is the biggest long-term trust issue with LLMs. When your user can’t bridge that gulf, you’ve built a black box. They’ll eventually stop trusting it.
The Explainability Problem Nobody’s Solving
In EdTech, and executive coaching is EdTech even if we don’t always dress it that way, recommendations aren’t like movie suggestions. If Netflix recommends a mediocre rom-com, nobody gets hurt. You scroll on.
If ExecReps recommends the wrong practice scenario to someone preparing for a board presentation next Tuesday, and they spend their limited practice time on a scenario that doesn’t stretch the right muscles? That’s someone’s career development time wasted. I was talking to a product leader last week, and he mentioned how frustrating it is when ‘AI’ gives him generic suggestions. He just wants to know why. So when they ask ‘why did the platform have me practice this?’, ‘well, the embedding similarity was high’ isn’t an answer.
Any product team that’s applied Nielsen’s Heuristics knows this tension. His sixth heuristic, Recognition over Recall, says users should never have to guess why the system made a decision. They should see the reasoning. With an LLM, the honest answer was we couldn’t show it. With math, we could.
Nir Eyal’s Hook Model shaped our thinking too. The Hook cycles through Trigger → Action → Variable Reward → Investment. In a coaching context, the variable reward needs to feel earned and understood, not random. If users can’t connect the recommendation to their own growth, the reward loop breaks. The thing I keep coming back to is this. We needed variability in the content surface, yes, but not opacity in the logic underneath.
Five Factors, Zero Magic
So we built what I now think of as the honest recommendation engine. Five scoring factors. Each weighted. Each grounded in learning science. And each, I’d later realize, maps to established behavioral frameworks that any product team would recognize:
1. Content Relevance. Does this scenario match what you need to practice? A structured mapping between your stated goals, your role, your industry, and the content metadata we’ve tagged on every scenario.
2. Difficulty Match. Straight from Vygotsky’s Zone of Proximal Development, which anyone who’s studied Csikszentmihalyi’s Flow theory will recognize. Optimal challenge sits just beyond current ability. Daniel Pink calls this the Mastery component of his Drive framework, the intrinsic pull toward getting better at something that matters. The engine doesn’t just serve content. It serves the right difficulty to keep users in that Flow channel.
3. Skill Gaps. Where are you weakest relative to where you need to be? If your scores show strong Command but shaky Eloquence, the system pushes you toward scenarios demanding clarity and articulation. The Kano Model would call this ‘must-be’ quality. Users expect a coaching platform to know where they need work. Not a delighter. Table stakes.
4. Recency. When did you last practice a particular skill area? Spaced repetition works. Kahneman and Tversky’s research on memory availability tells us the same thing from a different angle. Recently practiced skills feel more accessible than they are, creating an illusion of competence the system needs to counteract.
5. Diversity. This one’s mine, not from any textbook. I kept noticing in user testing that people got stuck in loops, practicing presentations over and over because that’s what felt comfortable. From a Hook Model perspective, this is where variable reward design becomes critical. Eyal is explicit: predictable rewards lose power. The diversity factor nudges you into unfamiliar territory. Difficult conversations, upward feedback, client escalations. The things you avoid are often the things you need most.
Each factor produces a normalized score. The weighted combination gives us a final ranking. No black box. Every recommendation traces back to defensible reasoning. ‘We recommended this because you haven’t practiced delivery skills in 12 days, this scenario is one level above your last difficulty rating, and it targets the dimension where your gap is widest.’
Norman would call that bridging the Gulf of Evaluation. Nielsen would call it Visibility of System Status. I just call it treating adults like adults.
141 Skills Walk Into a Bar
Let me be honest about a mistake here. It’s one that any PM who’s read Norman’s work on conceptual models should have seen coming.
When we first built skill tracking, I let users self-report their target skills. Free text. ‘What skills do you want to develop?’ Very user-friendly. Very product-manager-who-reads-too-many-UX-books, me included.
We ended up with 141 unique skills in the database. Think ‘Executive presence.’ Then ‘Executive communication.’ Then ‘Presence in meetings.’ Then ‘Being more present in executive meetings.’ Four users, four entries, functionally the same thing.
The recommendation engine couldn’t work on top of that. In Norman’s terms, we had a catastrophic conceptual model mismatch. Every user had built a different mental model of what they were working on, and the system had no shared language to operate from. You can’t do gap analysis when the gap dimensions are fuzzy, overlapping, and user-generated.
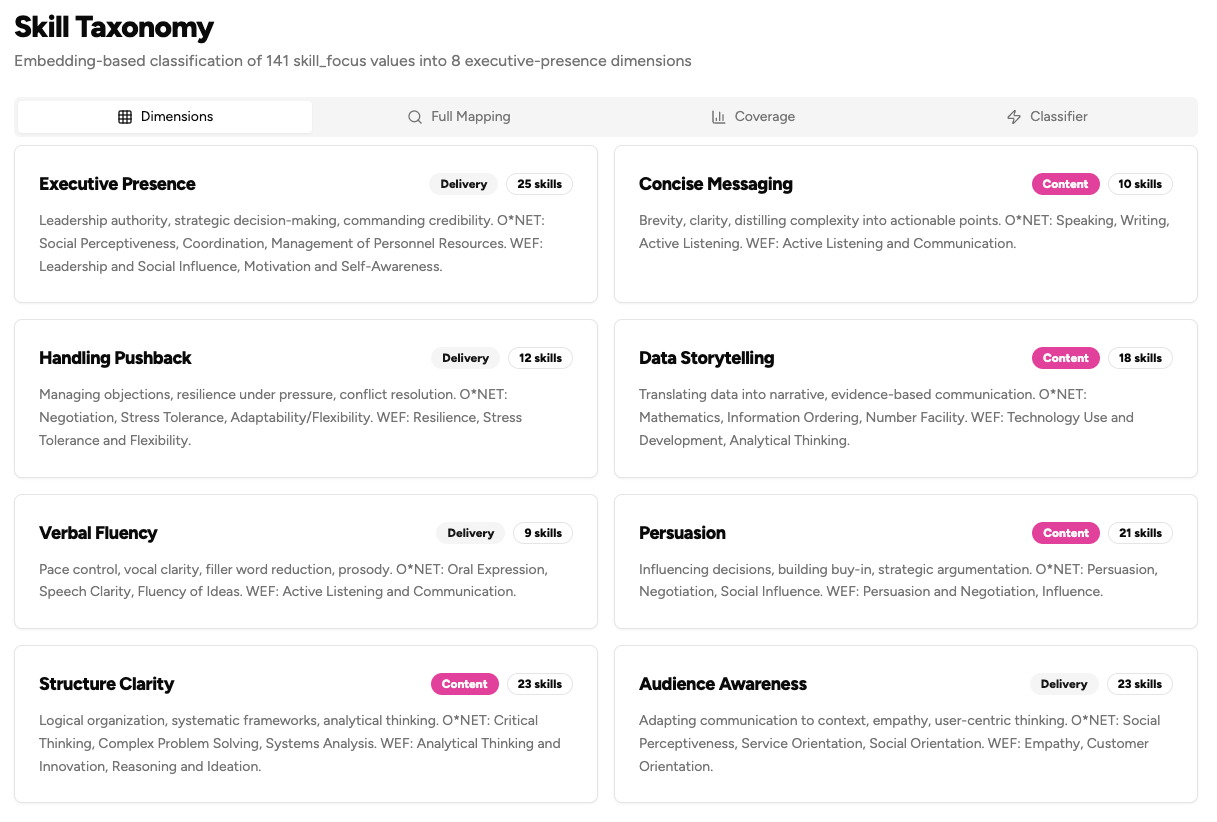
So we did something painful. We threw all 141 away and started from psychometric research. Validated communication competency frameworks. Published, peer-reviewed dimensions of what ‘communication skill’ means when you measure it rigorously.
We landed on eight dimensions. Eight.
That collapse, 141 to 8, was one of the hardest product decisions I’ve made. In Self-Determination Theory terms (Deci & Ryan), it felt like violating the Autonomy principle. It felt like telling users ‘we know better than you what you’re working on.’ The psychometric evidence was overwhelming though. When you let people self-categorize communication skills, they create endless synonyms and miss critical dimensions entirely. Almost nobody listed ‘consistency’ as a target, for example. I’m not sure if this is a universal human trait or specific to communication skills, but it’s a pattern I’ve seen often. Consistency, maintaining quality under pressure, across contexts, is one of the strongest predictors of communication effectiveness in the literature.
User-generated taxonomies feel democratic. Validated taxonomies work. The Kano Model has a concept for this. Users will say they want freeform input, but their satisfaction doesn’t improve from getting it. What improves satisfaction is getting recommendations that work.
Solving Cold Start Without Asking Boring Questions
The classic cold start problem. New user, no data, and you need good recommendations immediately. Most platforms solve this with a questionnaire. ‘Rate your interest in these 15 topics.’
BJ Fogg’s B=MAP model told us that was wrong. Behavior equals Motivation plus Ability plus Prompt. A new user arriving from their manager’s email has moderate motivation at best. A fifteen-question onboarding form tanks their Ability. Too much time, too much mental effort, too much friction. Fogg is clear: when motivation is low, make the action trivially easy. A questionnaire is the opposite of easy.
We built two things instead.
First: industry/role/seniority profiles. Before any user tells us anything personal, we know statistical priors. A VP of Engineering at a Series B startup has different communication challenges than a Marketing Director at a Fortune 500. We built baseline profiles from research. What skills matter at each seniority level, what scenarios each role encounters, what difficulty level fits each experience bracket.
Second, and this is the one I’m proudest of, the Challenge Picker and Confidence Slider.
Instead of asking ‘what do you want to improve?’ we show three real scenarios and let users pick which feels most relevant. Steve Krug would call this ‘Don’t Make Me Think.’ Recognition, not recall. Show options, let them point.
Then, before their first practice: a Confidence Slider. ‘How confident do you feel about this scenario?’ Zero to ten. Two seconds.
That slider is pure signal. It’s where Kahneman and Tversky’s work on cognitive bias becomes directly useful in product design. Someone who rates themselves 8/10 confidence and delivers a 550 EPS score has a calibration problem, what Kahneman calls overconfidence bias. Someone who rates 3/10 and delivers the same 550 is underestimating themselves. The recommendation engine treats them completely differently, and it should. The gap between self-assessment and performance is one of the richest signals any coaching product can capture.
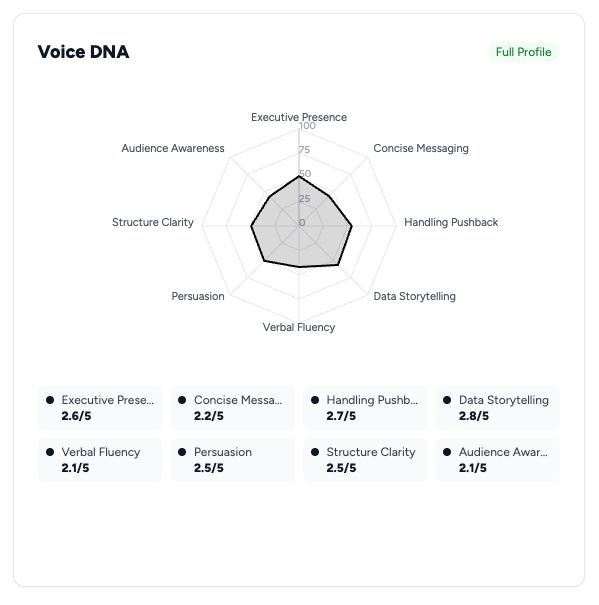
All of this runs without a single API call to any language model. Zero tokens. Zero latency. Zero risk of prompt injection or model drift affecting what learning path someone follows.
The Quiet Confidence of Boring Technology
I’m not anti-AI. ExecReps runs on AI, yes. Our assessment engine is genuinely powerful and would have been impossible three years ago. AI was the wrong tool for recommendations though, because the recommendation problem was well-defined enough to solve with math.
Here’s my rough heuristic, for what it’s worth:
Use AI when: the input is unstructured, the output needs to be generative, and you can’t write rules for what ‘good’ looks like. Assessment of free-form speech? That’s AI.
Use algorithms when: the input is structured, the output is a ranking, and you can define ‘good’ with research. Matching users to content? That’s math.
Use neither when: the problem is a UX problem disguised as a technical one.
There’s a confidence that comes from building something you can fully explain. When a user asks ‘why did you recommend this?’ and you can say ‘because your skill gap in Eloquence is 23% wider than your gap in Command, you haven’t practiced client-facing scenarios in 9 days, and this sits one difficulty tier above your last successful attempt’, that’s a different conversation than ‘our AI thought you’d like it.’
In executive coaching, where people are developing skills that affect their careers, their livelihoods, their sense of professional identity, they deserve the transparent answer. Someone making decisions about their own development should understand the reasoning behind the recommendations shaping that development.
Executive presence should not be a privilege. Neither should understanding why your learning platform steers you in a particular direction.

It’s not the flashiest thing we’ve built, I know. ‘Startup uses math instead of AI’ isn’t exactly clickbait. Still, when I look at our recommendation accuracy, users completing recommended scenarios at a significantly higher rate than self-selected ones, I think about that moment with the GPT–4 prompt written and ready to ship.
I’d delete that prompt again every time.